Overview
Contents
User programs run in unprivileged mode on Linux-based operating systems. When the programs require services from the kernel, they must use system calls. A system call is the only valid way to enter kernel mode (Supervisor/privileged mode).
This tutorial is about implementing a system call on an ARM-based Linux kernel. Access the entire source here.
Let us define an example system call pinfo. pinfo takes process with ID pid and a struct prcs_info as arguments and returns in-kernel information about the process. A system call handler must be implemented in the kernel to handle pinfo. We will use a small program to test pinfo. Finally, we will use Linux ptrace, to trace and gather statistics about pinfo system call.
Generally, user programs never have to directly call a system call. Instead, they call a wrapper around ‘library call’ implemented by standard C library, which makes the actual system call to the kernel. An an example, consider the call flow of standard ‘write‘ system call:
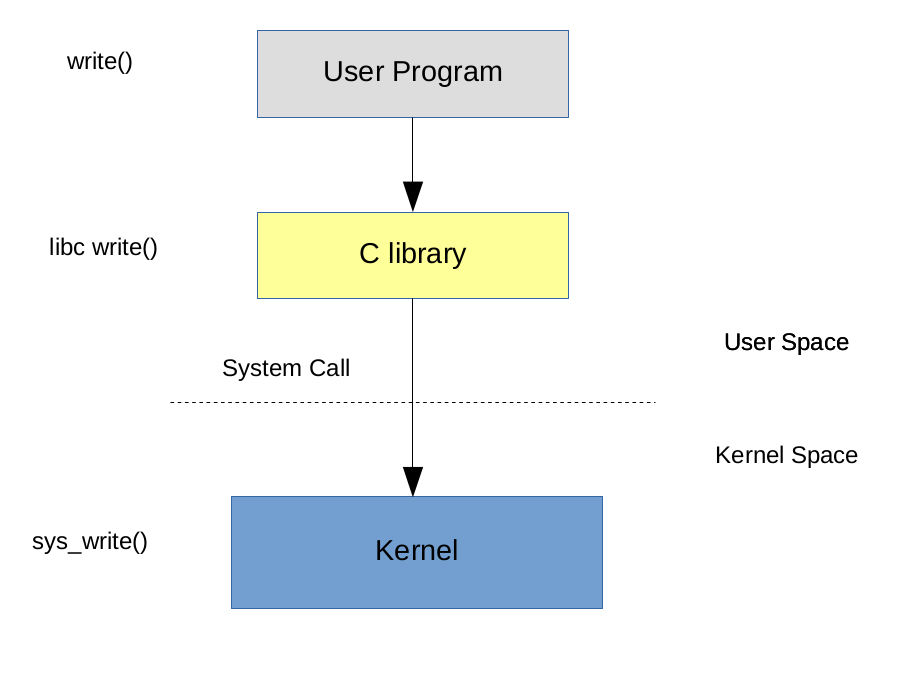
While defining a new system call is generally unnecessary (Linux provides plenty of system calls that satisfy most requirements), it is worthwhile to know the internal details of system call handling. It is very useful to know why the kernel returned an error for a syscall and to perform analysis of user programs, in terms of time spent in kernel.
Add System Call Handler in Kernel
A system call is handled by piece of code in kernel called system call handler. Each system call has a unique system call handler.
When user space makes a system call, it passes a system call number as argument to the kernel. The kernel holds system call table, which contains the addresses of routines to be called based on the system call number.
The system call numbers are defined in unistd.h . Therefore, the first step to define a new system call number is to add an entry into the system call table.
#define __NR_pinfo 285 __SYSCALL(__NR_pinfo, sys_pinfo) #undef __NR_syscalls //#define __NR_syscalls 285 #define __NR_syscalls 286
The actual system call handlers are implemented in kernel/sys.c . We will define our new system call handler in this file, at the end. To facilitate easy implementation of new system calls, kernel provides a MACRO SYSCALL_DEFINEx which converts system call numbers, arguments into a nice function prototype.
SYSCALL_DEFINEx is defined in include/linux/syscalls.h. The expansion chain of this macro is an unreadable mess, but finally it expands to:
asmlinkage long sys_syscallname
Since pinfo system call takes two arguments, let use the SYSCALL_DEFINE2 macro to define system call.
SYSCALL_DEFINE2(pinfo, struct prcs_info __user *, pf, pid_t, pid)
asmlinkage long sys_pinfo(struct prcs_info __user *pf, pid_t pid)
Where struct prcs_info is a newly-defined structure to pass process info from kernel to user space. We declare this structure in unistd.h (UAPI) so that we have a common, well-defined interface between kernel and user-space.
struct prcs_info {
int prio; // priority
long state; // -1 unrunnable, 0 runnable, >0 stopped
unsigned int cpu; // Current CPU
unsigned long nvcsw; // context switch count
unsigned long long start_time; // start time in ns
};
This structure is essentially a subset of struct task_struct in Linux kernel. Each process is described by the task_struct within the kernel. For pinfo, individual members of this struct gives us the required information about the process. We will simply copy interesting members of current task_struct to prcs_info to get information about the requested process.
Let us implement the body of the system call handler. We will start by verifying the arguments passed by user space, since incorrect arguments can crash the kernel and bring down entire system.
if (!pf || pid < 0) {
printk(KERN_ALERT "pinfo(): Invalid argument\n");
return -EINVAL;
}
If the arguments are wrong, we simply return the appropriate error codes from Linux errno.h. Next, we need to convert the pid to task_struct for the given process, which is a kernel structure for a specific process. Fortunately, there are helper functions and available for this purpose.
/* get task_struct from pid */
task = pid_task(find_get_pid(pid), PIDTYPE_PID);
if (!task) {
printk(KERN_ALERT "pinfo(): Invalid pid\n");
return -EINVAL;
}
Now that we have the task_struct representing the requested process, we simply fill the required struct members,
pif.prio = task->prio; pif.state = task->state; pif.cpu = task->cpu; pif.nvcsw = task->nvcsw; pif.start_time = task->start_time;
and copy this struct to the passed argument pf. However, remember that prcs_info * is a user-space pointer, and we cannot simply use pointers from user-space. Doing so would be catastrophic, as any user program could pass a bad pointer and access kernel info or crash the system.
Remember, kernel and userspace use different page tables. Kernel cannot access memory pointed to by user space pointers directly. Instead, kernel uses special functions: copy_to_user/copy_from_user to copy data to and from user space.
The implementation of these functions is architecture-specific: In ARM64, instructions STTR/LTTR are used, which allow kernel to use Load/Store instructions as if they had been executed at privilege level EL0 (user space). See implementation of ARM64 copy_to_user.
Putting everything together, this is the final system call handler:
SYSCALL_DEFINE2(pinfo, struct prcs_info __user *, pf, pid_t, pid)
{
unsigned long ret;
struct prcs_info pif;
struct task_struct *task;
printk(KERN_ALERT "pinfo(): invoked by user\n");
if (!pf || pid < 0) {
printk(KERN_ALERT "pinfo(): Invalid argument\n");
return -EINVAL;
}
/* get task_struct from pid */
task = pid_task(find_get_pid(pid), PIDTYPE_PID);
if (!task) {
printk(KERN_ALERT "pinfo(): Invalid pid\n");
return -EINVAL;
}
pif.prio = task->prio;
pif.state = task->state;
pif.cpu = task->cpu;
pif.nvcsw = task->nvcsw;
pif.start_time = task->start_time;
ret = copy_to_user(pf, &pif, sizeof(struct prcs_info));
if (ret) {
printk(KERN_ALERT "pinfo(): copy_to_user failed\n");
return -EINVAL;
}
return 0;
}
Now, once we compile the kernel we can verify that the new system call is registered using kallsyms feature, which lists the symbolic names and addresses of functions in the kernel. /proc/kallsyms should now have the following entry: (Assuming that the kernel is built with CONFIG_KALLSYMS)
ffffff80080b29a8 T SyS_pinfo
Where the first entry is the address of the symbol and T represents text (code) section.
pinfo system call is now ready to be used.
How are system calls trapped in kernel (ARMv8/AARCH64)?
In ARM systems, Linux kernel runs at EL1 exception level and the userspace runs at EL0. (If you are not familiar with exception levels, see a quick tutorial). When a user program requires services of kernel, the exception level must be changed from EL0 to EL1. To achieve this, user program executes svc instruction, passes the system call number along with system call arguments. (More commonly, user program calls a C library wrapper for the system call, and the C library executes an svc instruction.)
The ARM64-specific exception handling code is present in arch/arm64/kernel/entry.S
As a result of svc instruction, an exception is caused. When an exception occurs, the processor executes corresponding handler code in exception vector table. For changes from EL0->EL1, the vector table provided by VBAR_EL1 (Vector Based Address Register) is used. Since svc is a synchronous exception (i.e caused as a result of executing an instruction), the entry ‘sync’ from the vector table is selected.
ENTRY(vectors) kernel_ventry 1, sync_invalid // Synchronous EL1t kernel_ventry 1, irq_invalid // IRQ EL1t kernel_ventry 1, fiq_invalid // FIQ EL1t kernel_ventry 1, error_invalid // Error EL1t kernel_ventry 1, sync // Synchronous EL1h kernel_ventry 1, irq // IRQ EL1h kernel_ventry 1, fiq_invalid // FIQ EL1h kernel_ventry 1, error_invalid // Error EL1h kernel_ventry 0, sync // Synchronous 64-bit EL0 kernel_ventry 0, irq // IRQ 64-bit EL0 kernel_ventry 0, fiq_invalid // FIQ 64-bit EL0 kernel_ventry 0, error_invalid // Error 64-bit EL0 #ifdef CONFIG_COMPAT kernel_ventry 0, sync_compat, 32 // Synchronous 32-bit EL0 kernel_ventry 0, irq_compat, 32 // IRQ 32-bit EL0 kernel_ventry 0, fiq_invalid_compat, 32 // FIQ 32-bit EL0 kernel_ventry 0, error_invalid_compat, 32 // Error 32-bit EL0 #else kernel_ventry 0, sync_invalid, 32 // Synchronous 32-bit EL0 kernel_ventry 0, irq_invalid, 32 // IRQ 32-bit EL0 kernel_ventry 0, fiq_invalid, 32 // FIQ 32-bit EL0 kernel_ventry 0, error_invalid, 32 // Error 32-bit EL0 #endif END(vectors)
el0_sync: kernel_entry 0 mrs x25, esr_el1 // read the syndrome register lsr x24, x25, #ESR_ELx_EC_SHIFT // exception class cmp x24, #ESR_ELx_EC_SVC64 // SVC in 64-bit state b.eq el0_svc
After checking the type of exception (svc, in this case), svc handler is called (el0_svc):
el0_svc: adrp stbl, sys_call_table // load syscall table pointer mov wscno, w8 // syscall number in w8 mov wsc_nr, #__NR_syscalls el0_svc_naked: // compat entry point stp x0, xscno, [sp, #S_ORIG_X0] // save the original x0 and syscall number enable_dbg_and_irq ct_user_exit 1 ldr x16, [tsk, #TSK_TI_FLAGS] // check for syscall hooks tst x16, #_TIF_SYSCALL_WORK b.ne __sys_trace cmp wscno, wsc_nr // check upper syscall limit b.hs ni_sys mask_nospec64 xscno, xsc_nr, x19 // enforce bounds for syscall number ldr x16, [stbl, xscno, lsl #3] // address in the syscall table blr x16 // call sys_* routine b ret_fast_syscall
Finally the kernel syscall handler (sys_* routine) is called from the system call table.
Prepare Userspace for System Call
Let us create a simple test program pinfo_test to test pinfo
Now, we need to have a common data structure between the kernel and userspace. Linux kernel uapi/ directory contains userspace API: include/uapi/asm-generifc/unistd.h . This is where we can declare struct prcs_info.
struct prcs_info {
int prio; // priority
long state; // -1 unrunnable, 0 runnable, >0 stopped
unsigned int cpu; // Current CPU
unsigned long nvcsw; // context switch count
unsigned long long start_time; // start time in ns
};
In pinfo_test, let us initialize the structure.
struct prcs_info pif =
{
.prio = -1,
.state = -1, /* -1 unrunnable, 0 runnable, >0 stopped */
.cpu = 0,
.nvcsw = 0,
.start_time = 0,
};
As a test, we can use getpid to get the PID of calling process, i.e current process – pinfo_test. You can test with pid = 1 for init process, or add logic to parse /proc/ for PID of any process.
Now, we will simply call pinfo with the arguments. In case pinfo returns an error, we should check the return code. When system calls returns an error, the global variable errno is set by C library to the error code returned by the kernel.
ret = pinfo(&pif, pid);
if (ret < 0) {
printf("System call error %s\n", strerror(-ret));
return -1;
}
Finally we will print the values of process info.
printf("Process info : \n");
printf("Process priority : %d\n", pif.prio);
printf("Process state : %ld\n", pif.state);
printf("Current CPU : %d\n", pif.cpu);
printf("Context switch count : %lu\n", pif.nvcsw);
printf("Process start time (ns) : %llu\n", pif.start_time);
Note that since C library does not know yet know about our new system call pinfo, which actually makes the system call. There are two ways to handle this
1. Direct System Call – Function within pinfo_test program to bypass C library and make the system call directly.
OR
2. C library wrapper function.
Direct System Call
User applications can call the kernel system call directly from inside of the application.
To enter kernel mode to request service from Linux kernel, ARM64 provides svc call. svc (Supervisor Call) instruction changes current exception level from Since svc is ARM assembly instruction, we will need to use asm directive to call it from within a C function.
In this case, the user must provide the arguments in appropriate registers, as defined by ARM64 Procedure Call Standard.
For AARCH64, registers X0-X7 are ‘argument registers’, i.e the system call handler uses
argument 1: -> X0
argument 2: -> X1
The actual system call number is passed through X8 register.
If the system call returns an error, we must validate the error code. X0 is the return register per the ARM64 ABI.
Putting all of this together, let us implement the actual function using C inline assembly. Most compilers support inline assembly (See a quick guide on GCC inline assembly.)
int pinfo(struct prcs_info *pif, pid_t pid)
{
int err;
err = 0;
asm("MOV x8, #285;" //x8 holds syscall no
"SVC #0;" // supervisor call
"MOV %[result], x0" : [result] "=r" (err) //copy return code to err
);
return err;
}
System Call through libc
Most user applications do not call a system call directly. For convenience, most implementations of standard C library provide a wrapper around the system call. These wrappers provide and set errno and provide architecture-specific assembly stubs to make the system call with syscall number.
The example in this tutorial is based on Android’s libc implementation, bionic.
Let us declare the function prototype user-space C library in bionic’s unistd.h
int pinfo(struct prcs_info *pif, pid_t pid) __attribute__((weak));
Notice the attritube weak. This attribute makes the symbol ‘weak’, which implies that if we define the function pinfo in our program, the linker will override the ‘weak’ definition for the ‘strong’ one. Usually, C library functions are declared as ‘weak’ so that custom implementations by a user program can override the standard functions.
See an excellent guide on ‘weak’ symbols.
Let us implement the wrapper pinfo:
extern int __pinfo();
int pinfo(struct prcs_info *pif, pid_t pid)
{
/* No need to make syscall if arguments are wrong */
if (!pif || pid < 0)
return -EINVAL;
return __pinfo(pif);
}
The wrapper calls the assembly function __pinfo which takes care of svc call and argument setup. A small optimization here is checking of arguments<>. If wrong arguments are passed, we can return. Note that __pinfo must be declared as ‘extern’ for linker’s benefit.
Bionic provides a convenience script gensyscalls.py, which generates assembly stub for adding a new syscall. Add following entry in SYSCALLS.TXT and run gensyscall.py to generate assembly stub:
int pinfo(struct prcs_info *pif, pid_t pid) arm64
The assembly file is generated by this script: pinfo.S:
ENTRY(__pinfo)
mov x8, __NR_pinfo
svc #0
cmn x0, #(MAX_ERRNO + 1)
cneg x0, x0, hi
b.hi __set_errno_internal
ret
END(__pinfo)
.hidden __pinfo
This assembly stub is similar to what we did for a direct system call: Copy System call number in x8 register and make a supervisor call with svc.
Upon return from system call, bionic code additionally checks the return value to set global errno. The user program can directly check the value of errno to see if system call returned any error.
System Call Tracing with Linux ptrace
ptrace is a powerful feature of Linux kernel which allows us to trace the system call and also provides various statistical information about the traced process. ptrace is used by debuggers to attach to and debug a process as well as strace, a powerful utilty to examine system calls made by a process. ptrace is also a system call, and we will use strace utility to trace pinfo system call. See strace usage.
You can analyze the performance of a system call, observe the bottlenecks and see which system call consumed maximum time using strace. In our case, since pinfo handler does not perform any time-consuming operations (e.g I/O operations, allocating new memory), very little time is spent in the kernel.
To know how ‘strace’ works internally, see an excellent guide on strace.
NOTE: The stock version of strace will not know about our newly added syscall pinfo, so we must modify strace code to make it aware of pinfo. This change makes strace associate the intercepted system call number with pinfo function.
Let us summarize the system calls made by pinfo_test by using -c option
#strace -c pinfo-test % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 47.51 0.000896 90 10 write 17.39 0.000328 2 138 mmap 9.81 0.000185 9 21 fstat 9.76 0.000184 8 23 read 9.60 0.000181 2 96 prctl 5.94 0.000112 2 59 mprotect 0.00 0.000000 0 1 ioctl 0.00 0.000000 0 8 fstatfs 0.00 0.000000 0 4 faccessat 0.00 0.000000 0 23 2 openat 0.00 0.000000 0 21 close 0.00 0.000000 0 8 pread64 0.00 0.000000 0 9 readlinkat 0.00 0.000000 0 37 2 newfstatat 0.00 0.000000 0 1 set_tid_address 0.00 0.000000 0 38 futex 0.00 0.000000 0 1 clock_gettime 0.00 0.000000 0 1 sigaltstack 0.00 0.000000 0 9 rt_sigaction 0.00 0.000000 0 89 munmap 0.00 0.000000 0 1 execve 0.00 0.000000 0 2 getrandom 0.00 0.000000 0 1 pinfo ------ ----------- ----------- --------- --------- ---------------- 100.00 0.001886 601 4 total
As you can see, the majority of time ‘pinfo_test’ spent is in ‘write’ and ‘mmap’ syscalls, which are memory access and File I/O operations respectively.
If wrong arguments are used, strace will report it as well:
# strace -c pinfo_test -1 % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- 0.00 0.000000 0 1 1 pinfo
Source